other posts
-
Mar 19, 2018
Nod-o-Meter
-
Feb 23, 2018
dsp audio amplifier
-
Jan 23, 2018
variational autoencoder interactive demos with deeplearn.js
-
Sep 15, 2017
backpropagation using random feedback weights
They have a problem at Quora.com. There are 13+M questions are already on their platform and ~13k questions added everyday. People hop on there and ask questions that have been asked and answered before. It is not humanly possible to read that many questions and flag the duplicates… unless you are her.
To address the issue they developed their own algorithms to detect duplicate question. On top of that, a while ago Quora published their first public dataset of question pairs publicly for machine learning (ML) engineers to see if anyone can come up with a better algorithm to detect duplicate questions, and they created a competition on Kaggle.
Here is how the competition works: ML engineers and ML engineer wannabes -cough-me-cough- who have too much time on their hand (or are not properly supervised at work), download the competition’s training set (which looks like fig. 1) and develop machine learning algorithms that learn by going through the examples in the training set. The training set is usually manually labeled. In this case, 1 or 0 in the is_duplicate column indicates whether the questions are identical. Here the training set contains ~420K question pairs.
| id | question1 | question2 | is_duplicate |
|---|---|---|---|
| 1 | Why my answers are collapsed? | Why is my answer collapsed at once? | 0 |
| 2 | How do I post a question in Quora? | How do I ask a question in Quora? | 1 |
| 3 | Can I fit my booboos in a 65ml jar? | Is 1 baba worth 55 booboo (おっぱい) ☃? | 0 |
Beside the training set, they also publish a test set which does not have the answers (is_duplicate column is empty). Your job is to develop an algorithm that learns to detect a duplicate question pair by looking at the training dataset. After it is done learning, you’ll have it go through each question pair in the test set and fill out the is_duplicate column. There are 2,345,796 question pairs in the test set.
linear regression on cosine similarity
First to get my feet wet and establish a baseline, I coded up a very basic logistic regression model in Tensorflow. The model took only one feature as input, and that was cosine similarity of two sentences. Where each word in a question was represented by a vector from the pre-trained GloVe word vectors. This way each question becomes a matrix. Multiplying the matrices, summing up the elements, and normalizing by question lengths should give us a number (feature) that is proportional to how similar the questions are. I called this feature the overlap_score. This should work for two reasons:
-
If a word is present in both questions, then dot product of that word by itself gives highest possible result, 1 (vectors are normalized)
-
Word vectors of synonym words most often have similar vectors. Which again means their dot product should be a higher number.
So this feature should not only capture same word appearing in the questions, but also a word and its synonym. This is great, right?! right?!
If you have been into machine learning, you know that one feature doesn’t get you very far. So needless to say, my single feature logistic regression had an accuracy that was slightly better than chance! facing the horrible performance, I decided to plot this feature against the ground truth to see if a relationship can be seen. fig. 2 shows how the overlap_score is related to the ground truth. As you can see there is no obvious relationship between the two.
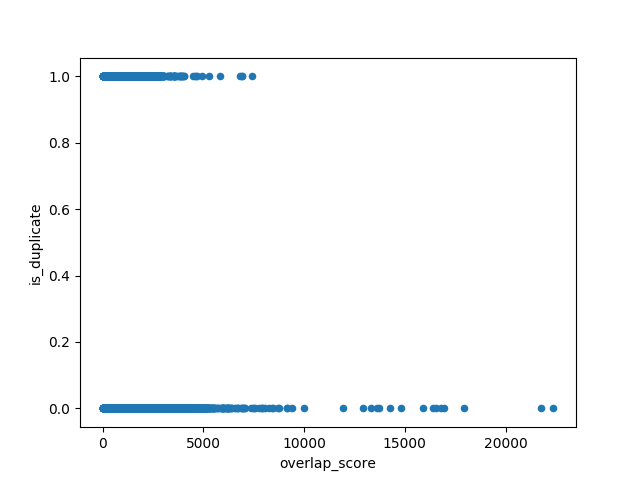
At this point I could try adding more features. That would have a definitely improved the result (as described by Abhishek here), but I wanted to try something sexier than logistic regression for selfish reasons.
Decomposable Attention Model
One day during my morning swim in arxiv.org, I came across a curious paper titled: A Decomposable Attention Model for Natural Language Inference. The authors bragged about the state of the art performance of their model with an order of magnitude less variables than the next best thing. With about a week to go to the competition deadline, I decided to give this ago, and implemented their model in Tensorflow.
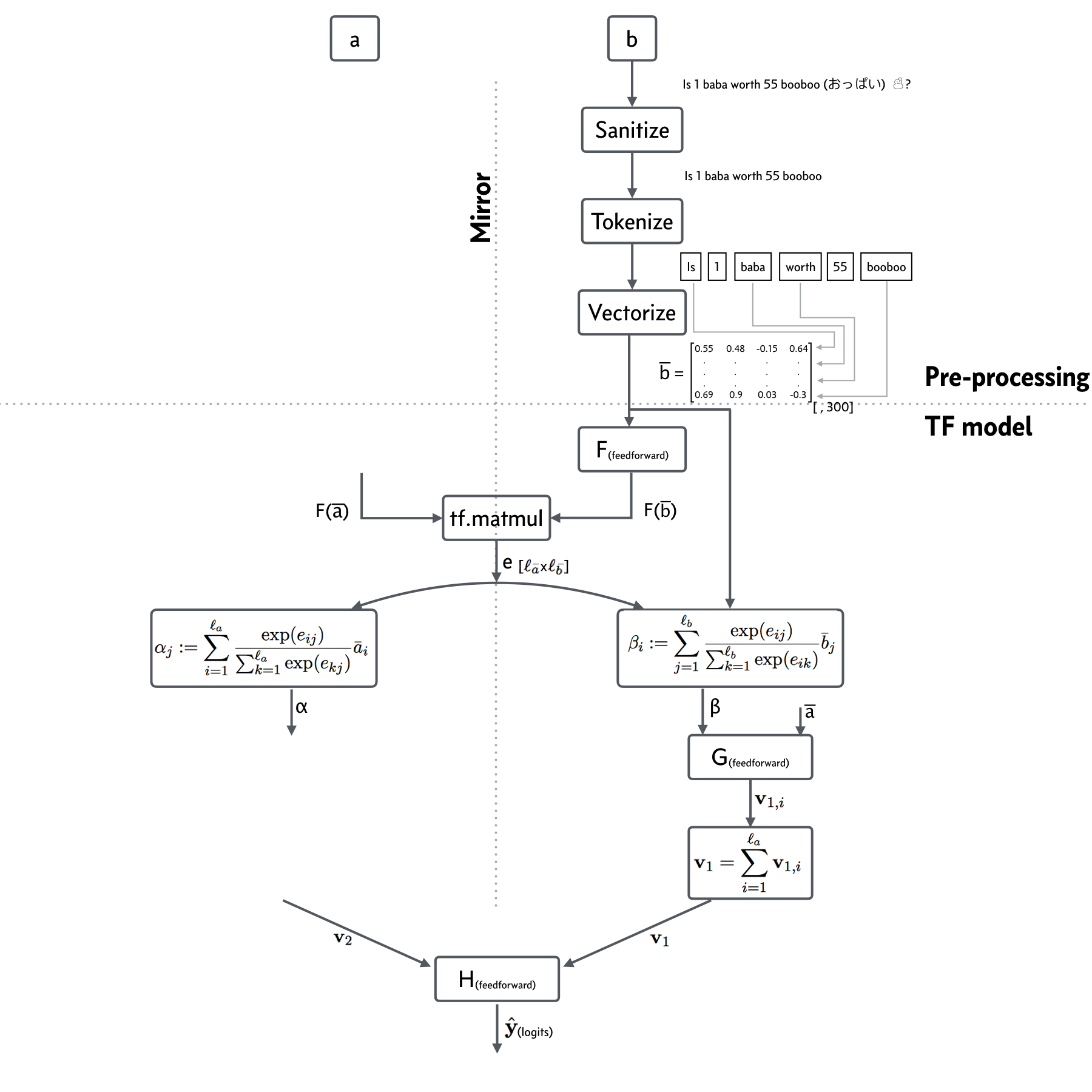
The model was originally tested on the Stanford Natural Language Inference (SNLI) dataset by the authors of the paper. I adapted this model for use in the Quora competition. Fig. 3 below depicts the model. Please note that the model is symmetric, and I didn’t draw the left side. (In my implementation, F, G, and H are each two layers deep. So this is not a very deep model overall. )
Training
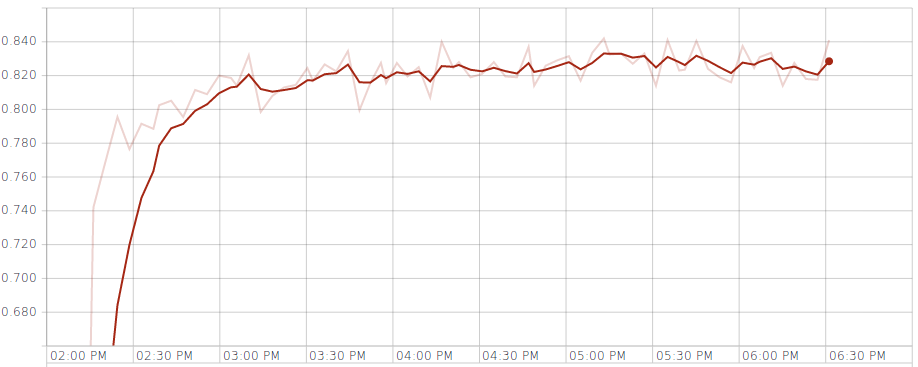
I used vanilla SGD with constant learning rate. I spent very little time tuning the hyper parameters, just enough to make sure the loss is decreasing. Fig. 4 shows that the cross validation accuracy flats out and stays around 0.82 after 10 epochs.
Then I let the model run for 50 epochs. Fig. 5 shows the accuracy on the training set.
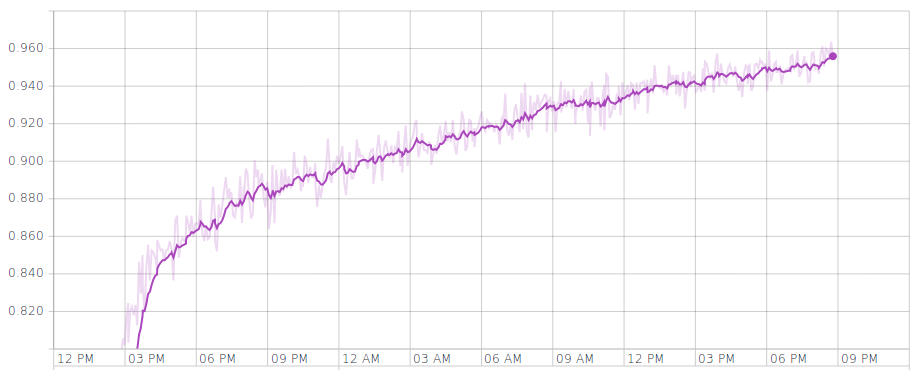
Comparing this to fig. 4, you'll see even though the accuracy on x-val set flats out after about 6 epochs, The accuracy on the training set keeps going up.
Performance - speed
As you can see from fig. 4 and fig. 5 the model is not very fast. That is attributed to the fact that my implementation doesn’t use batching. Here is why:
The sentences come in various lengths, then they are multiplied together, concatenated, and so on. This creates matrices of various sizes along the way. This makes batching difficult. You are probably thinking why not pad all sentence to a fix length? The average sentence length is ~12 words with standard deviation of 6 words, and the longest sentence is ~123 words. So padding all sentences to 123 words, would not yield any gains.
One way to overcome this issue is to bucket the sentences according to their lengths, and padding sentences in each bucket to max length of that bucket. For instance, sentences with length 0 to 20 will be padded to 20, sentences with length between 20 to 40 will be padded to 40, and so on. This way groups of sentences with the same length can be batched together. However, the deadline was fast approaching, so I didn’t implement this bucketing & batching approach.
Without any batching, the gain from using a GPU was not that impressive. The model processes ~220 sentence pairs per second on my dedicated linux box with a GTX-1060 6Gb GPU. GPU utilization stands around 10%, so the GPU is clearly underutilized. The model runs at ~160 sentence pairs per second on my 2013 MacBook Pro with 2.4GHz i5 CPU. (As a side note, I saw a 12x speed improvement with my GPU on the Tensorflow’s PTB example!)
Performance - accuracy
The model achieved ~95% accuracy on training data and 82% on x-val. set after 50 epochs (Which is similar to what Quora’s internal team had achieved with the same method). This model achieved a logloss of 0.448 on the competition test set, which landed me at ~2200 on the leaderboard. To put this in perspective, first team on the leaderboard had a logloss of 0.116.
Future improvements
Time did not allow me to use TF-IDF, Stop Words, any kind of feature engineering or ensembling. I also did not implement the “infra-sentence” attention explained in the paper. Also for the sake of simplicity, I used a pretty crude pre-processing technique that gets entirely rid of some useful information that the model could leverage, like numbers and out-of-vocabulary words. I think all these areas of improvement are worth exploring and would result in noticeable improvement.
Unforeseen challenges
One problem that I spent a ridiculous amount of time on, was reading the CSV files and feeding them to Tensorflow. Both Python’s CSV reader and Tensorflow’s CSV decoder threw exceptions at various points in the file. The only hassle free CSV reader was the one from Pandas.
Tensorflow documentation can also be a lot better. Frequently, I found myself looking at the code rather than the documentation to understand what it’s doing. This is something that I expect to get better as Tensorflow matures. Right now, things are moving too fast in their codebase and documention is a step behind.
Code
My Tensorflow implemetaion for the Decomposable Attention Model can be found here: siarez/sentence_pair_classifier
further reading
If you are interested in learning more about what others have done on this problem make sure to check out these links: